Video synthesis methods rapidly improved in recent years, allowing easy creation of synthetic humans. This poses a problem, especially in the era of social media, as synthetic videos of speaking humans can be used to spread misinformation in a convincing manner. Thus, there is a pressing need for accurate and robust deepfake detection methods, that can detect forgery techniques not seen during training.
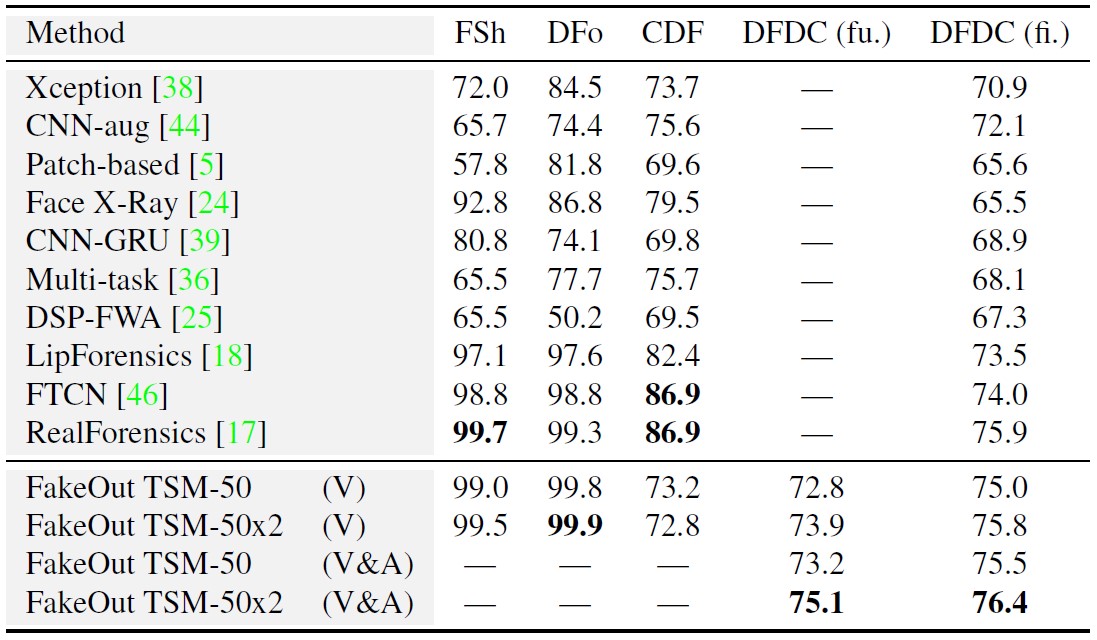
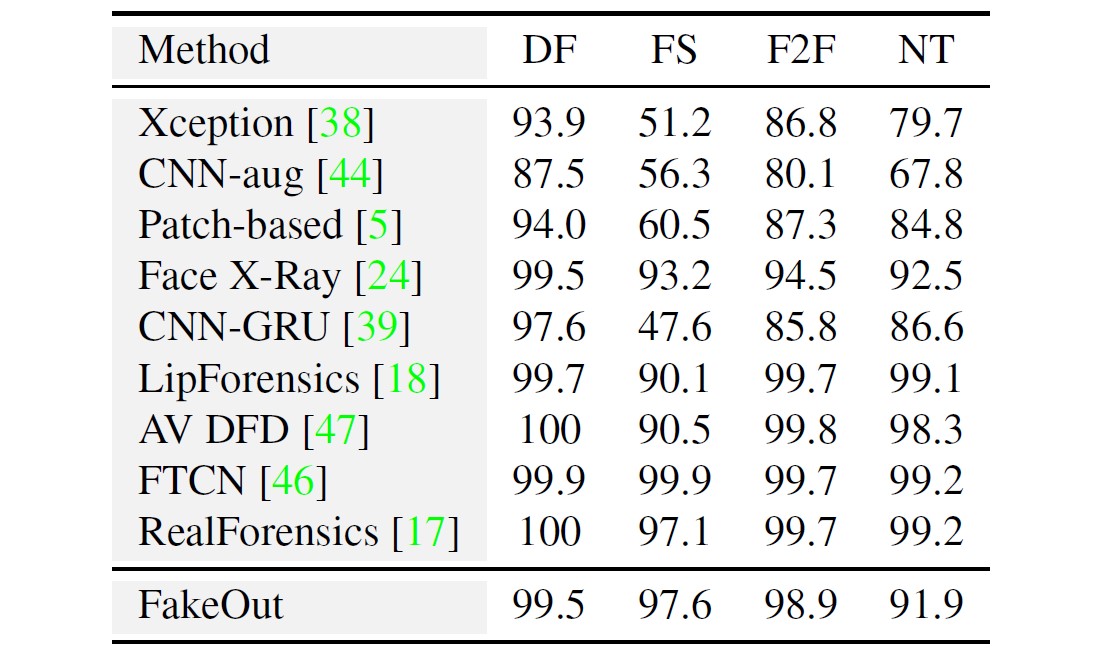
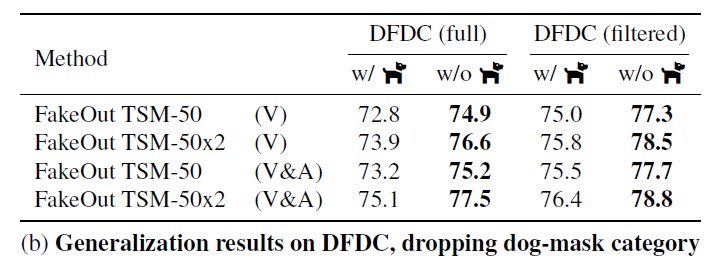
In this work, we explore whether this can be done by leveraging a multi-modal, out-of-domain backbone trained in a self-supervised manner, adapted to the video deepfake domain. We propose FakeOut; a novel approach that relies on multi-modal data throughout both the pre-training phase and the adaption phase. We demonstrate the efficacy and robustness of FakeOut in detecting various types of deepfakes, especially manipulations which were not seen during training. Our method achieves state-of-the-art results in cross-manipulation and cross-dataset generalization. This study shows that, perhaps surprisingly, training on out-of-domain videos (i.e., videos with no speaking humans), can lead to better deepfake detection systems. Code is available on GitHub.
@article{knafo2022fakeout,
title={FakeOut: Leveraging Out-of-domain Self-supervision for Multi-modal Video Deepfake Detection},
author = {Knafo, Gil and Fried, Ohad},
journal={arXiv preprint arXiv:2212.00773},
year={2022}
}